Serverless LLM Inference: The Real Cost of AWS Bedrock vs. GCP Vertex vs. Azure OpenAI in 2026

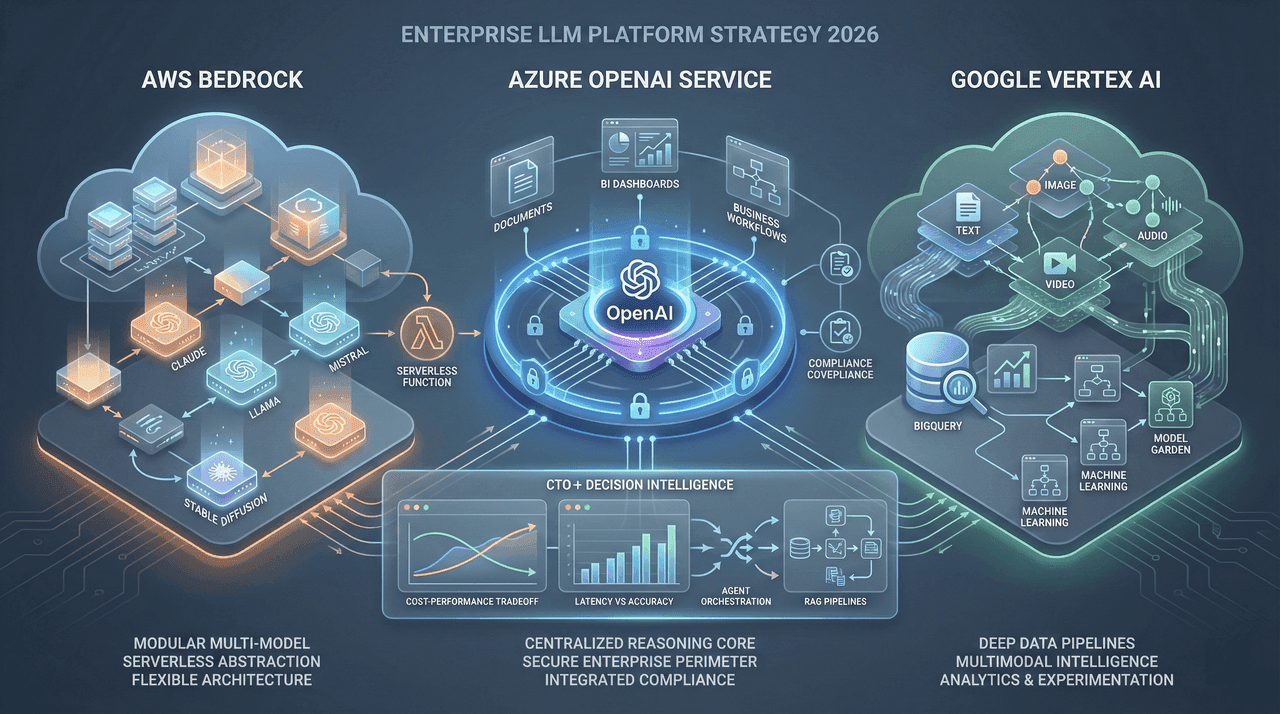
Most enterprises overspend 32–57% on LLM inference due to invisible serverless costs—cold starts, throttling, orchestration overhead, observability, and vector infrastructure that never appear on pricing pages. This deep-dive exposes the real economics of AWS Bedrock, GCP Vertex AI, and Azure OpenAI in 2026, using production-scale data, compliance constraints, and architectural tradeoffs. If you’re a CTO, cloud architect, or FinOps lead, this guide shows where budgets actually leak—and how to design inference systems that scale without financial surprises.
Most enterprises overspend 32–57% on LLM inference due to invisible serverless costs—cold starts, throttling, orchestration overhead, observability, and vector infrastructure that never appear on pricing pages. This deep-dive exposes the real economics of AWS Bedrock, GCP Vertex AI, and Azure OpenAI in 2026, using production-scale data, compliance constraints, and architectural tradeoffs. If you’re a CTO, cloud architect, or FinOps lead, this guide shows where budgets actually leak—and how to design inference systems that scale without financial surprises.
Team Note
The full technical details for this topic are available upon request for enterprise clients. We frequently update these entries as patterns evolve in the AI ecosystem.