We Build AI
That Works.
From concept to production — custom AI solutions for enterprises that demand results. LLM fine-tuning, RAG systems, AI agents, and more.
What We
Build.
Deep expertise in AI, mobile engineering, and cloud infrastructure — delivering production-grade solutions that transform businesses.
AI & Machine Learning
Building production-ready AI systems — custom LLMs, RAG pipelines, computer vision, and intelligent agents for enterprise use cases.
Mobile & Cross-Platform
High-performance mobile applications with enterprise-grade security, cross-platform native performance, and seamless API integration.
Cloud & Backend Infrastructure
Scalable, resilient backend systems — from API design to cloud deployment, database engineering, and real-time data pipelines.
The Tools We Master.
A comprehensive stack of languages, frameworks, and infrastructure tools to build resilient, production-grade solutions.
Core Languages
Multi-paradigm mastery.
Architectural Frameworks
Production-grade backbones.
Infrastructure
Global scale backbones.
AI & Intelligence
Custom LLMs & Vision.
Security & Logic
Hardened core logic.
DevOps & CI/CD
Automated lifecycles.
Expert Tooling
Precision engineering.
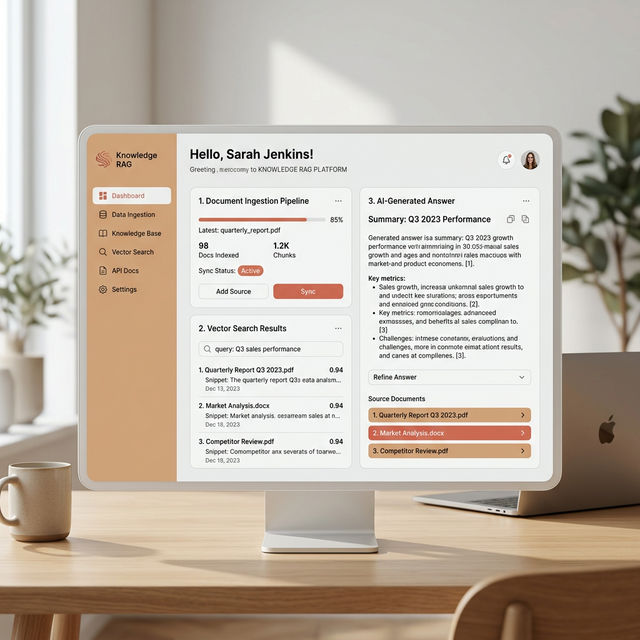
Privacy-First AI Intelligence
Echo AI — Digital Twin Platform
A GPU-accelerated digital twin platform combining RAG with advanced LLMs. Privacy-focused AI that understands your business through document ingestion, vector search, and contextual inference — all running locally.
Our Process
Architecting with Precision
Discovery
Understand your problem, data landscape, and success metrics.
Architecture
Design the optimal AI architecture, tech stack, and integration plan.
Build & Train
Implement models, pipelines, and APIs with rigorous testing.
Deploy & Scale
Production deployment with monitoring, CI/CD, and performance optimization.
Case Studies
Our Work
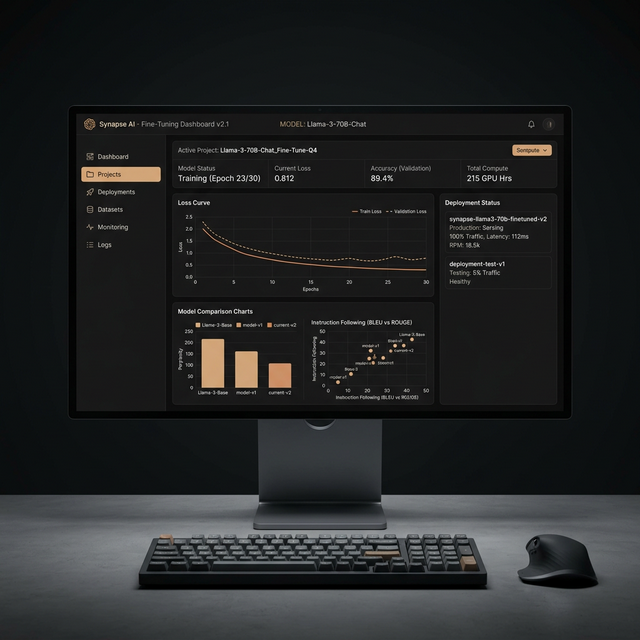
Sentinel — AI Robotics System
Intelligent robotics platform with advanced computer vision, voice-controlled navigation, and autonomous decision-making. Real-time object detection, text-to-speech feedback, and mobile app integration for remote surveillance and interaction.
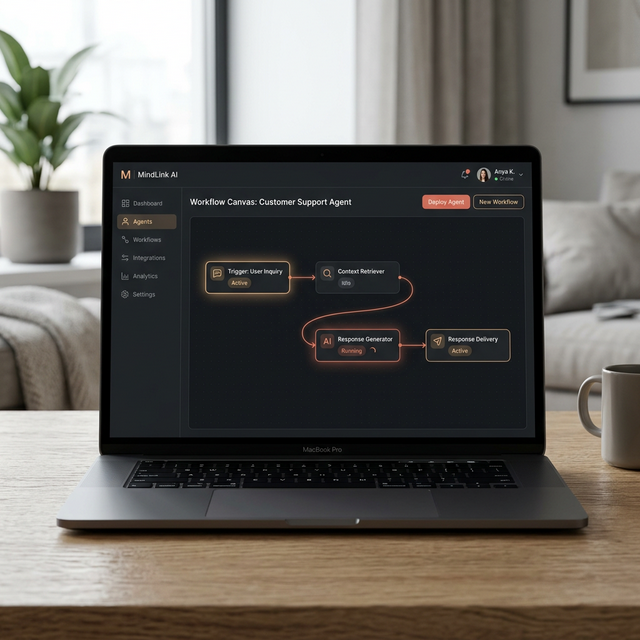
Nexus — AI Agent Builder
Enterprise-grade AI agent orchestration platform. Build, deploy, and monitor autonomous agents with a visual workflow canvas. Supports multi-agent collaboration, tool integration, and human-in-the-loop checkpoints for mission-critical workflows.

NeuroPilot — AI Pin Assistant
AI-powered wearable assistant embedded in a compact pin form factor. Real-time contextual awareness via on-device vision, natural language processing, and proactive notifications. Speech-to-action with multi-modal input for hands-free productivity.
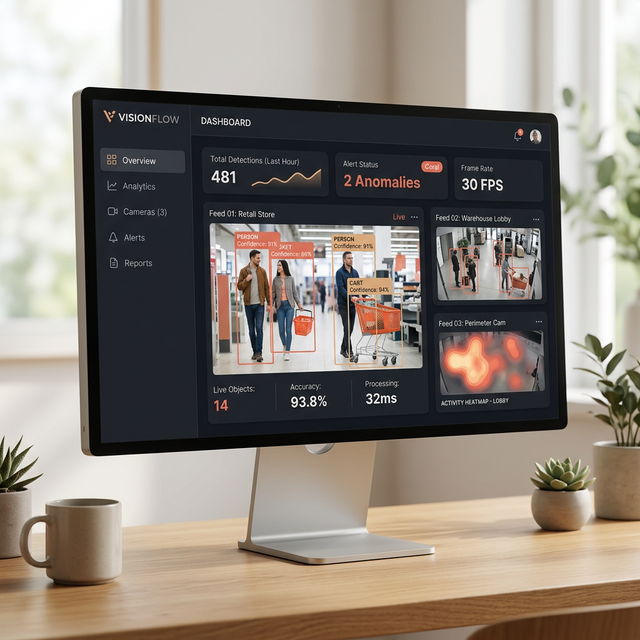
Prism — Computer Vision Analytics
Real-time visual intelligence platform for industrial quality control and safety monitoring. Features object detection (YOLO), anomaly identification, multi-camera feeds with heatmap overlays, and automated alerting — deployed on edge devices for sub-100ms inference.
Questions & Answers
Frequently Asked Questions
Get In Touch
Start Your
AI Journey.
We prioritize deep technical engagements over quick fixes. Whether you need a custom LLM pipeline, a mobile application, or enterprise architecture — reach out to start the conversation.