Production RAG Architecture That Scales: Vector Databases, Chunking Strategies, and Cost Optimization for 2025
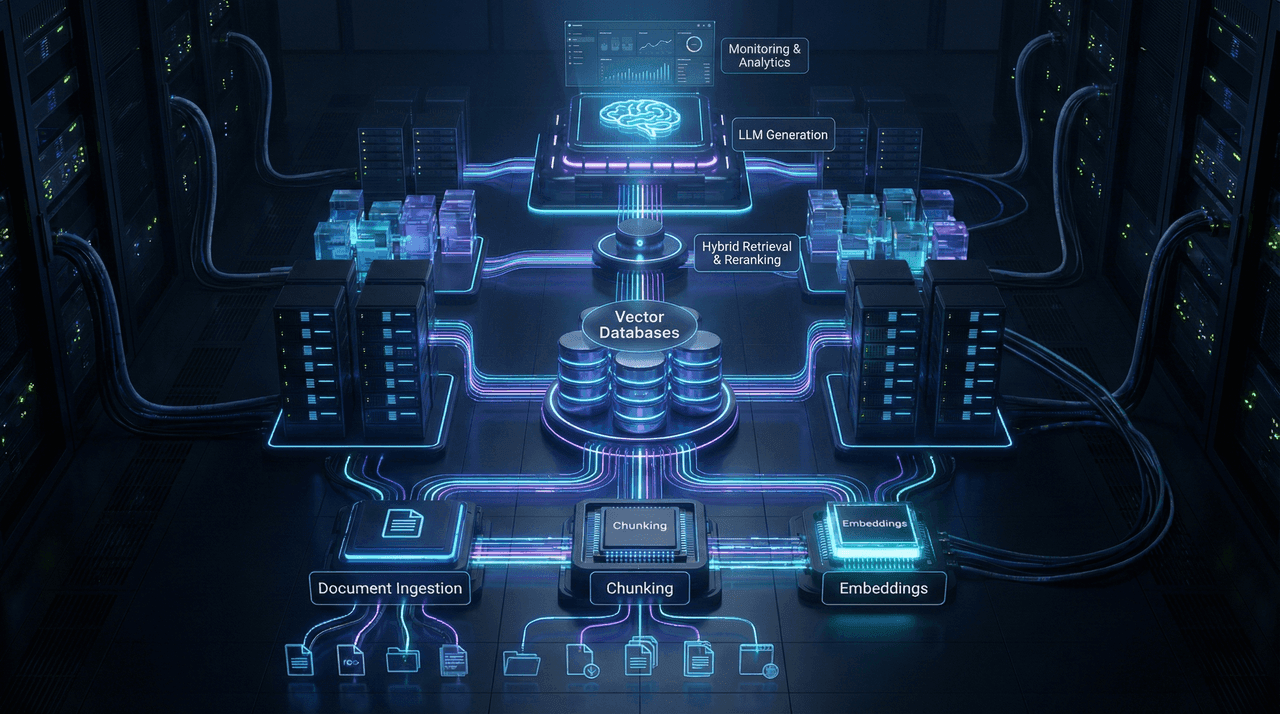
This deep-dive explores how to design production-grade Retrieval-Augmented Generation (RAG) systems that scale reliably from thousands to millions of documents. Learn how to choose the right vector databases, implement advanced chunking strategies, optimize retrieval pipelines, and reduce operational costs by up to 80%—all while maintaining accuracy, latency SLAs, and enterprise-grade security.
This deep-dive explores how to design production-grade Retrieval-Augmented Generation (RAG) systems that scale reliably from thousands to millions of documents. Learn how to choose the right vector databases, implement advanced chunking strategies, optimize retrieval pipelines, and reduce operational costs by up to 80%—all while maintaining accuracy, latency SLAs, and enterprise-grade security.
Team Note
The full technical details for this topic are available upon request for enterprise clients. We frequently update these entries as patterns evolve in the AI ecosystem.