Kubernetes for AI Workloads: GPU Scheduling & Autoscaling Guide (2026)
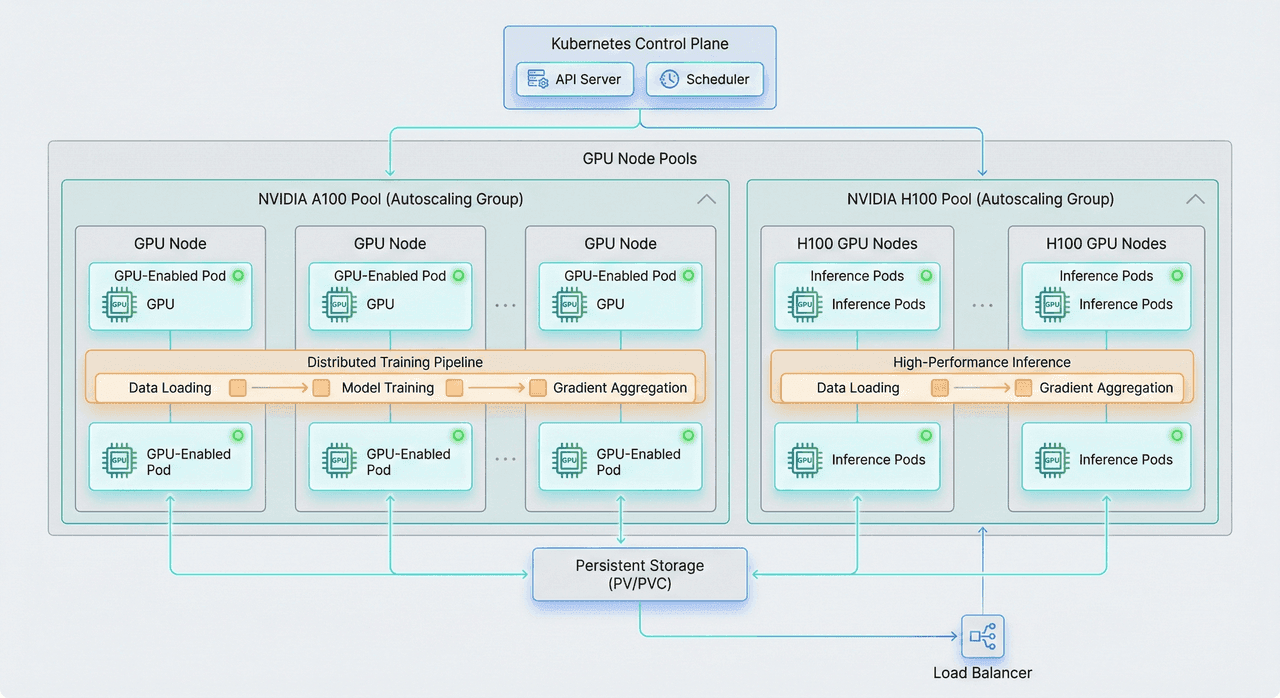
A deep technical, production-grade guide to running AI and ML workloads on Kubernetes in 2026. This article covers GPU scheduling, MIG-based partitioning, Kueue and gang scheduling, DCGM-powered observability, multi-node distributed training, and intelligent autoscaling—showing how enterprises can increase GPU utilization from 20% to 70–80% while cutting infrastructure costs by up to 70%.
A deep technical, production-grade guide to running AI and ML workloads on Kubernetes in 2026. This article covers GPU scheduling, MIG-based partitioning, Kueue and gang scheduling, DCGM-powered observability, multi-node distributed training, and intelligent autoscaling—showing how enterprises can increase GPU utilization from 20% to 70–80% while cutting infrastructure costs by up to 70%.
Team Note
The full technical details for this topic are available upon request for enterprise clients. We frequently update these entries as patterns evolve in the AI ecosystem.